By submitting this form, you consent to Qualys' privacy policy
Email or call us at 1 (800) 745-4355
Discover, monitor & reduce your modern web app and API attack surface with advanced, AI-powered TruRisk™ platform
web applications & APIs discovered & scanned for maximum coverage
vulnerabilities detected, including OWASP Top 10, with continuous monitoring
critical issues prioritized for faster remediation with integrated workflows

Qualys Web Application Scanning (WAS) is an industry-leading cloud-based AppSec solution, providing DAST, API security, deep learning-based web malware detection and AI-powered scanning. Qualys WAS detects runtime vulnerabilities, OWASP Top 10, OWASP API Top 10, misconfigurations, PII & sensitive data exposures, web malware, compliance issues, drift from OpenAPI (OAS v3) specifications and more through automated end-to-end crawling and testing.

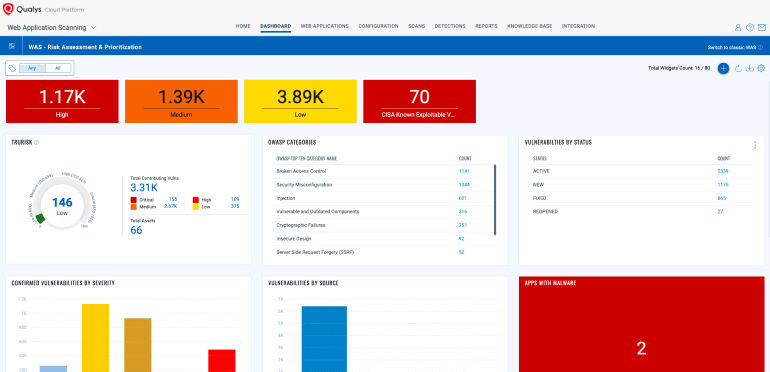
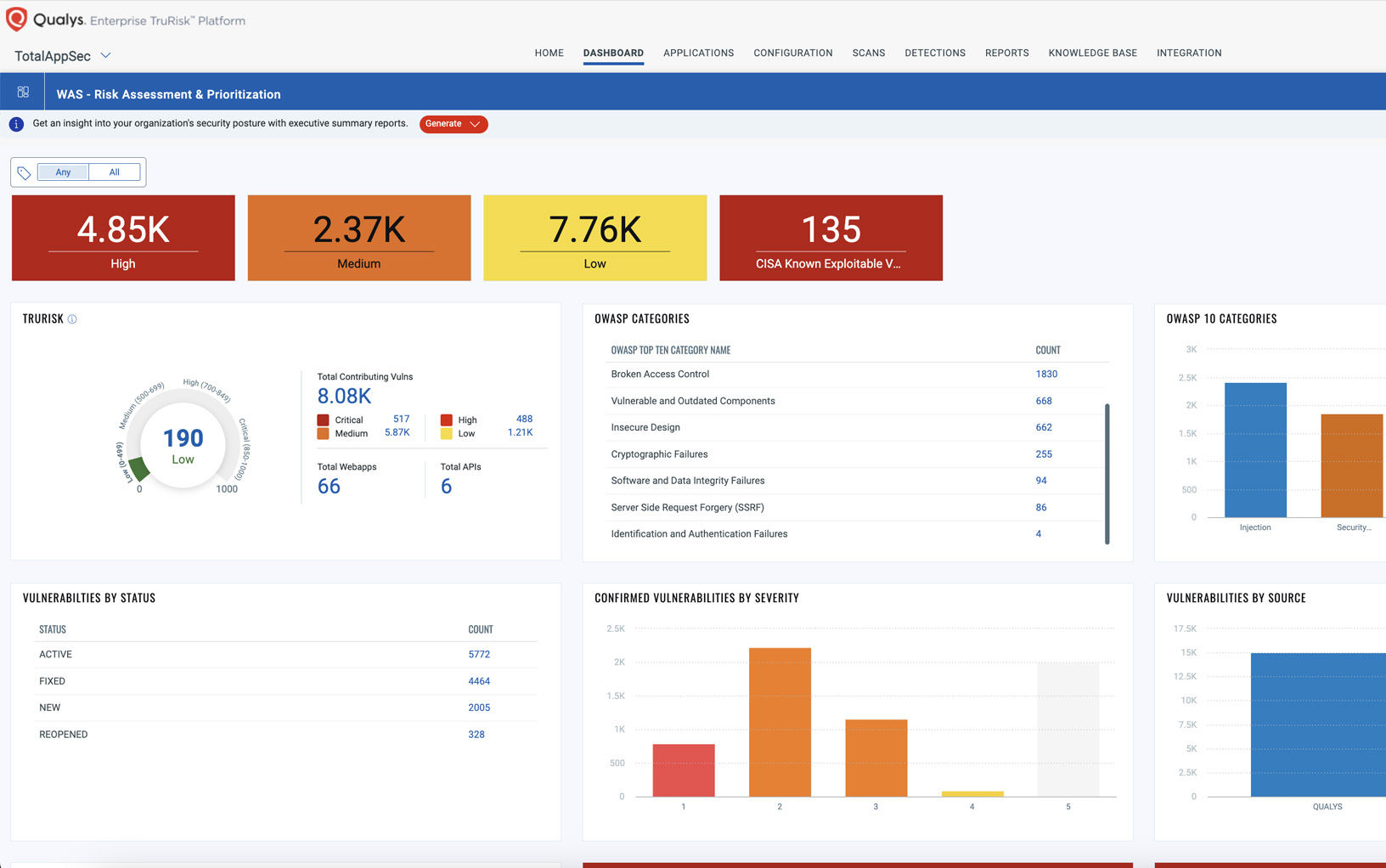
The Enterprise TruRisk Platform provides you with a unified view of your entire cyber risk posture so you can efficiently aggregate and measure all Qualys & non-Qualys risk factors in a unified view, communicate cyber risk with context to your business, and go beyond patching to eliminate the risk that threatens the business in any area of your attack surface.

See how Peter orchestrates a strategic response to an emergent security threat - a new authentication bypass vulnerability - by utilizing the powerful capabilities of Qualys WAS and securing a vast web application landscape of 2000+ web apps.